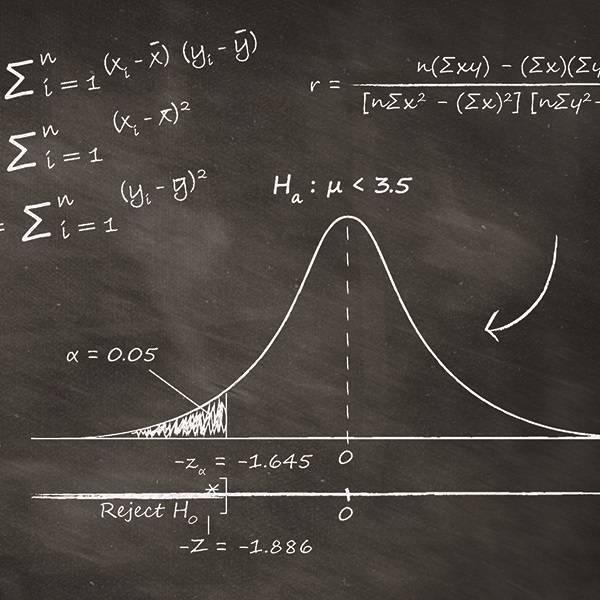
Do we still need the statistical threshold value (p<0.05)?
It’s often statistics that determine whether or not a new drug is approved, or a political decision is made. But can we really rely on their significance?

Photo: Valérie Chételat
The controversy over significance tests is as old as the method itself. Most criticisms arise because of one of two things: either the statistical models are being applied incorrectly, or the results themselves have been incorrectly interpreted. If carried out properly, however, testing hypotheses remains useful and important.

Photo: Valérie Chételat
In order to draw conclusions and make decisions, we often test whether the p-value lies under five percent (p<0.05). Regrettably, the significance of the p-value is so difficult to understand that most researchers draw false conclusions from it. There is a widespread, erroneous belief that a p-value over five percent proves that there is no effect.
The theory behind it is certainly not easy to understand. But applying it today is actually simple, thanks to computer programs. This is great for many users, because they would prefer to engage properly with their research topic, and not with matters of methodology. They want to determine whether an effect is significant or not, and simply place their blind trust in their computer program. Regrettably, ‘significant’ today doesn’t mean that something is automatically relevant. This means that many investigations lead to conclusions that are statistically untenable. So some of the arguments raised by critics are correct. The statistical significance of the p-value should be used less frequently. It would often be better to describe the estimated effect and how precise it is.
Testing hypotheses nevertheless remains a highly valuable method when you have to make informed decisions and to weigh up benefits and risks – such as when a new drug or therapy is being tested, for example. But good statistical planning in advance is essential, and this ought to be improved considerably in many disciplines.
For example, if researchers would like to show that two treatments differ in their impact, then they would have to determine in advance how they are going to measure that impact. They would also have to explain how big the desired effect ought to be in order for it to be substantively relevant. This purely technical step is indispensable for your planning. You can then take this as the basis for calculating your sample size. If it’s too small, then you can’t demonstrate any relevant effect; if it’s too big, irrelevant effects might become significant. Many don’t realise that planning a hypothesis test is closely connected to how the results are interpreted. In order to make more people aware of this, I therefore propose that this information be published before a study is actually conducted. Already today, there are specialist scientific journals that publish such study protocols in advance. This trend will continue.
Besides the hypothesis test, careful planning can also have other, positive consequences for academic life. The focus of the discussion should thus be shifted away from isolated methodological aspects to the overall scholarly context instead.
Thomas Fabbro is a biologist and lectures at the University of Basel. He is the head of Clinical Research Infrastructure at the Clinical Trial Unit of the Basel University Hospital.
There are other problems with the p-value. Even when researchers use the p-value correctly, things can go wrong in practice. When biologists come out with a correctly formulated statement like “We found no significant connection between the duration of the hunting season and the population size of a species of animal”, some politicians will take this as proof that there is no such connection. But instead of using the p-value, the biologists ought to have demonstrated the degree of connection in question. This would allow others to estimate how the future population of that species will develop according to the duration of the hunting season – bearing in mind the current state of knowledge. Using this information as a basis, the different interest groups involved could then decide jointly how long the hunting season should last.
It is not possible to make a decision based on the data if a result is reduced to a p-value larger or smaller than five percent. Because whether or not the threshold is undercut or exceeded is determined solely by the sample size. Just because we might create more data doesn’t change any biological connections. Reducing everything to the p-value means that we lose information about the strength of those connections.
A good decision is one that has been adapted to the situation at hand, and weighs up different alternatives. In the case of a highly endangered animal, even weak proof of a decrease in its population can suffice to justify protective measures. But in the case of a far more populous animal, we would only act if there were strong proof of a decrease in its numbers. To apply the same criterion to all cases, as with p<0.05, can lead to arbitrary decisions without paying due consideration to the consequences. And that is irresponsible.
Fränzi Korner-Nievergelt is a biologist and the owner of the statistics office Oikostat. She also lectures at ETH Zurich and works at the Swiss Ornithological Institute Sempach.
Photo: Valérie Chételat
The controversy over significance tests is as old as the method itself. Most criticisms arise because of one of two things: either the statistical models are being applied incorrectly, or the results themselves have been incorrectly interpreted. If carried out properly, however, testing hypotheses remains useful and important.
The theory behind it is certainly not easy to understand. But applying it today is actually simple, thanks to computer programs. This is great for many users, because they would prefer to engage properly with their research topic, and not with matters of methodology. They want to determine whether an effect is significant or not, and simply place their blind trust in their computer program. Regrettably, ‘significant’ today doesn’t mean that something is automatically relevant. This means that many investigations lead to conclusions that are statistically untenable. So some of the arguments raised by critics are correct. The statistical significance of the p-value should be used less frequently. It would often be better to describe the estimated effect and how precise it is.
Testing hypotheses nevertheless remains a highly valuable method when you have to make informed decisions and to weigh up benefits and risks – such as when a new drug or therapy is being tested, for example. But good statistical planning in advance is essential, and this ought to be improved considerably in many disciplines.
For example, if researchers would like to show that two treatments differ in their impact, then they would have to determine in advance how they are going to measure that impact. They would also have to explain how big the desired effect ought to be in order for it to be substantively relevant. This purely technical step is indispensable for your planning. You can then take this as the basis for calculating your sample size. If it’s too small, then you can’t demonstrate any relevant effect; if it’s too big, irrelevant effects might become significant. Many don’t realise that planning a hypothesis test is closely connected to how the results are interpreted. In order to make more people aware of this, I therefore propose that this information be published before a study is actually conducted. Already today, there are specialist scientific journals that publish such study protocols in advance. This trend will continue.
Besides the hypothesis test, careful planning can also have other, positive consequences for academic life. The focus of the discussion should thus be shifted away from isolated methodological aspects to the overall scholarly context instead.
Thomas Fabbro is a biologist and lectures at the University of Basel. He is the head of Clinical Research Infrastructure at the Clinical Trial Unit of the Basel University Hospital.
Photo: Valérie Chételat
In order to draw conclusions and make decisions, we often test whether the p-value lies under five percent (p<0.05). Regrettably, the significance of the p-value is so difficult to understand that most researchers draw false conclusions from it. There is a widespread, erroneous belief that a p-value over five percent proves that there is no effect.
For example, a Canadian study in 2017 found that children whose mothers took an anti-depressant during pregnancy are 1.6 times as likely to suffer from autism. But the p-value lay just over five percent, which means that the effect was not actually statistically significant. The authors then drew the false conclusion that an anti-depressant has no impact on the risk of autism. And yet an increased risk of 2.6 would still have been compatible with the data. Such false conclusions can arise because the belief is so widespread that anything above the threshold of five percent for a p-value upends a study’s conclusions.
There are other problems with the p-value. Even when researchers use the p-value correctly, things can go wrong in practice. When biologists come out with a correctly formulated statement like “We found no significant connection between the duration of the hunting season and the population size of a species of animal”, some politicians will take this as proof that there is no such connection. But instead of using the p-value, the biologists ought to have demonstrated the degree of connection in question. This would allow others to estimate how the future population of that species will develop according to the duration of the hunting season – bearing in mind the current state of knowledge. Using this information as a basis, the different interest groups involved could then decide jointly how long the hunting season should last.
It is not possible to make a decision based on the data if a result is reduced to a p-value larger or smaller than five percent. Because whether or not the threshold is undercut or exceeded is determined solely by the sample size. Just because we might create more data doesn’t change any biological connections. Reducing everything to the p-value means that we lose information about the strength of those connections.
A good decision is one that has been adapted to the situation at hand, and weighs up different alternatives. In the case of a highly endangered animal, even weak proof of a decrease in its population can suffice to justify protective measures. But in the case of a far more populous animal, we would only act if there were strong proof of a decrease in its numbers. To apply the same criterion to all cases, as with p<0.05, can lead to arbitrary decisions without paying due consideration to the consequences. And that is irresponsible.
Fränzi Korner-Nievergelt is a biologist and the owner of the statistics office Oikostat. She also lectures at ETH Zurich and works at the Swiss Ornithological Institute Sempach.